Live visualization on a map
With stackstac.show or stackstac.add_to_map , you can display your data on an interactive ipyleaflet map within your notebook. As you pan and zoom, the portion of the dask array that’s in view is computed on the fly.
By running a Dask cluster colocated with the data, you can quickly aggregate hundreds of gigabytes of imagery on the backend, then only send a few megabytes of pixels back to your browser. This gives you a very simplified version of the Google Earth Engine development experience, but with much more flexibility.
Limitations
This functionality is still very much proof-of-concept, and there’s a lot to be improved in the future:
Doesn’t work well on large arrays. Sadly, loading a giant global DataArray and using the map to just view small parts of it won’t work—yet. Plan on only using an array of the area you actually want to look at (passing bounds_latlon= stackstac.stack
Resolution doesn’t change as you zoom in or out.
Communication to Dask can be slow, or seem to hang temporarily.
Requires opening port 8000 (only accessible over localhost), which may be blocked in some restrictive environments.
You definitely will need a cluster near the data for this (or to run on a beefy VM in us-west-2
You can sign up for a Coiled account and run clusters for free at https://cloud.coiled.io/ — no credit card or username required, just sign in with your GitHub or Google account, then connect to your cloud provider account (AWS or GCP).
Client
Client-6f5f3f1a-6f7e-11ed-9177-acde48001122
Launch dashboard in JupyterLab
Cluster Info
ClusterBeta
stackstac-show
Scheduler Info
Scheduler
Scheduler-8b5de941-1f90-41c8-9207-ded9036c6312
Workers
Worker: stackstac-show-worker-049e8b75ad
Comm: tls://10.0.45.55:41827
Total threads: 4
Dashboard: http://10.0.45.55:8787/status
Memory: 14.95 GiB
Nanny: tls://10.0.45.55:43953
Local directory: /scratch/dask-worker-space/worker-rvylh17j
Worker: stackstac-show-worker-19beb02fba
Comm: tls://10.0.42.127:45283
Total threads: 4
Dashboard: http://10.0.42.127:8787/status
Memory: 14.94 GiB
Nanny: tls://10.0.42.127:37543
Local directory: /scratch/dask-worker-space/worker-qndwgkyh
Worker: stackstac-show-worker-2119d2ec0b
Comm: tls://10.0.44.90:45025
Total threads: 4
Dashboard: http://10.0.44.90:8787/status
Memory: 14.95 GiB
Nanny: tls://10.0.44.90:43867
Local directory: /scratch/dask-worker-space/worker-ph924lk7
Worker: stackstac-show-worker-3be649d711
Comm: tls://10.0.40.99:37369
Total threads: 4
Dashboard: http://10.0.40.99:8787/status
Memory: 14.94 GiB
Nanny: tls://10.0.40.99:45391
Local directory: /scratch/dask-worker-space/worker-3kszwm95
Worker: stackstac-show-worker-6a3c64a450
Comm: tls://10.0.44.164:37275
Total threads: 4
Dashboard: http://10.0.44.164:8787/status
Memory: 14.94 GiB
Nanny: tls://10.0.44.164:37879
Local directory: /scratch/dask-worker-space/worker-wciiamf5
Worker: stackstac-show-worker-7f5329d5ff
Comm: tls://10.0.38.243:37437
Total threads: 4
Dashboard: http://10.0.38.243:8787/status
Memory: 14.95 GiB
Nanny: tls://10.0.38.243:46747
Local directory: /scratch/dask-worker-space/worker-9kwf14rs
Worker: stackstac-show-worker-9cca0b9e7b
Comm: tls://10.0.40.190:41259
Total threads: 4
Dashboard: http://10.0.40.190:8787/status
Memory: 14.95 GiB
Nanny: tls://10.0.40.190:43953
Local directory: /scratch/dask-worker-space/worker-1gegxfsf
Worker: stackstac-show-worker-c20e4dfb55
Comm: tls://10.0.41.75:42667
Total threads: 4
Dashboard: http://10.0.41.75:8787/status
Memory: 14.95 GiB
Nanny: tls://10.0.41.75:42551
Local directory: /scratch/dask-worker-space/worker-3bmhilfc
Worker: stackstac-show-worker-dfe73e356c
Comm: tls://10.0.45.247:39505
Total threads: 4
Dashboard: http://10.0.45.247:8787/status
Memory: 14.94 GiB
Nanny: tls://10.0.45.247:34553
Local directory: /scratch/dask-worker-space/worker-zj2hv29k
Search for Sentinel-2 data overlapping our map
CPU times: user 116 ms, sys: 11.8 ms, total: 128 ms
Wall time: 1.15 s
<IPython.display.GeoJSON object>
Create the time stack
Important: the resolution you pick here is what the map will use, regardless of zoom level! When you zoom in/out on the map, the data won’t be loaded at lower or higher resolutions. (In the future, we hope to support this.)
Beware of zooming out on high-resolution data; you could trigger a massive amount of compute!
CPU times: user 42.8 ms, sys: 2.7 ms, total: 45.5 ms
Wall time: 43.7 ms
Persist the data we want to view
By persisting all the RGB data, Dask will pre-load it and store it in memory, ready to use. That way, we can tweak what we show on the map (different composite operations, scaling, etc.) without having to re-fetch the original data every time. It also means tiles will load much faster as we pan around, since they’re already mostly computed.
It’s generally a good idea to persist somewhere before stackstac.show
As a rule of thumb, try to persist after the biggest, slowest steps of your analysis, but before the steps you might want to tweak (like thresholds, scaling, etc.). If you want to tweak your big slow steps, well… be prepared to wait (and maybe don’t persist).
<xarray.DataArray 'stackstac-04aaa9bf6fc59f590a424ab757077d03' (time: 24,
band: 3,
y: 2624, x: 2622)>
dask.array<getitem, shape=(24, 3, 2624, 2622), dtype=float64, chunksize=(1, 1, 1024, 1024), chunktype=numpy.ndarray>
Coordinates: (12/52)
* time (time) datetime64[ns] 2020-04-01...
id (time) <U24 'S2B_13SDA_20200401_...
* band (band) <U12 'red' 'green' 'blue'
* x (x) float64 3e+05 ... 5.097e+05
* y (y) float64 4.1e+06 ... 3.89e+06
mgrs:utm_zone int64 13
... ...
raster:bands (band) object [{'nodata': 0, 'da...
gsd (band) object 10 10 10
common_name (band) object 'red' 'green' 'blue'
center_wavelength (band) object 0.665 0.56 0.49
full_width_half_max (band) object 0.038 0.045 0.098
epsg int64 32613
Attributes:
spec: RasterSpec(epsg=32613, bounds=(300000, 3890160, 509760, 4100...
crs: epsg:32613
transform: | 80.00, 0.00, 300000.00|\n| 0.00,-80.00, 4100080.00|\n| 0.0...
resolution: 80 dask.array<chunksize=(1, 1, 1024, 1024), meta=np.ndarray>
Array
Chunk
Bytes
3.69 GiB
8.00 MiB
Shape
(24, 3, 2624, 2622)
(1, 1, 1024, 1024)
Dask graph
648 chunks in 4 graph layers
Data type
float64 numpy.ndarray
24
1
2622
2624
3
Coordinates: (52)
time
(time)
datetime64[ns]
2020-04-01T18:03:50.186000 ... 2...
array(['2020-04-01T18:03:50.186000000', '2020-04-01T18:03:54.215000000',
'2020-04-01T18:04:04.327000000', '2020-04-01T18:04:08.595000000',
'2020-04-03T17:53:53.071000000', '2020-04-03T17:53:57.251000000',
'2020-04-03T17:54:07.524000000', '2020-04-03T17:54:10.679000000',
'2020-04-06T18:03:49.954000000', '2020-04-06T18:03:53.989000000',
'2020-04-06T18:04:04.095000000', '2020-04-06T18:04:08.369000000',
'2020-04-08T17:53:53.544000000', '2020-04-08T17:53:57.705000000',
'2020-04-08T17:54:08.005000000', '2020-04-08T17:54:11.154000000',
'2020-04-11T18:03:49.084000000', '2020-04-11T18:03:53.113000000',
'2020-04-11T18:04:03.225000000', '2020-04-11T18:04:07.492000000',
'2020-04-13T17:53:56.019000000', '2020-04-13T17:54:00.148000000',
'2020-04-13T17:54:10.480000000', '2020-04-13T17:54:13.625000000'],
dtype='datetime64[ns]') id
(time)
<U24
'S2B_13SDA_20200401_0_L2A' ... '...
array(['S2B_13SDA_20200401_0_L2A', 'S2B_13SCA_20200401_0_L2A',
'S2B_13SDV_20200401_0_L2A', 'S2B_13SCV_20200401_0_L2A',
'S2A_13SDA_20200403_0_L2A', 'S2A_13SCA_20200403_0_L2A',
'S2A_13SDV_20200403_0_L2A', 'S2A_13SCV_20200403_0_L2A',
'S2A_13SDA_20200406_0_L2A', 'S2A_13SCA_20200406_0_L2A',
'S2A_13SDV_20200406_0_L2A', 'S2A_13SCV_20200406_0_L2A',
'S2B_13SDA_20200408_0_L2A', 'S2B_13SCA_20200408_0_L2A',
'S2B_13SDV_20200408_0_L2A', 'S2B_13SCV_20200408_0_L2A',
'S2B_13SDA_20200411_0_L2A', 'S2B_13SCA_20200411_0_L2A',
'S2B_13SDV_20200411_0_L2A', 'S2B_13SCV_20200411_0_L2A',
'S2A_13SDA_20200413_0_L2A', 'S2A_13SCA_20200413_0_L2A',
'S2A_13SDV_20200413_0_L2A', 'S2A_13SCV_20200413_0_L2A'],
dtype='<U24') band
(band)
<U12
'red' 'green' 'blue'
array(['red', 'green', 'blue'], dtype='<U12') x
(x)
float64
3e+05 3.001e+05 ... 5.097e+05
array([300000., 300080., 300160., ..., 509520., 509600., 509680.]) y
(y)
float64
4.1e+06 4.1e+06 ... 3.89e+06
array([4100080., 4100000., 4099920., ..., 3890400., 3890320., 3890240.]) mgrs:utm_zone
()
int64
13
updated
(time)
<U24
'2022-11-06T14:31:19.801Z' ... '...
array(['2022-11-06T14:31:19.801Z', '2022-11-06T07:22:51.762Z',
'2022-11-06T10:14:16.681Z', '2022-11-06T10:15:25.721Z',
'2022-11-06T07:20:43.428Z', '2022-11-06T10:21:31.642Z',
'2022-11-06T07:21:36.990Z', '2022-11-06T07:20:40.737Z',
'2022-11-06T07:05:45.085Z', '2022-11-06T10:21:35.973Z',
'2022-11-06T10:14:20.981Z', '2022-11-06T07:20:38.463Z',
'2022-11-06T07:06:10.399Z', '2022-11-06T07:37:18.786Z',
'2022-11-06T10:14:26.677Z', '2022-11-06T07:19:38.224Z',
'2022-11-06T14:31:20.528Z', '2022-11-06T14:29:35.970Z',
'2022-11-06T10:14:16.074Z', '2022-11-06T07:13:16.911Z',
'2022-11-06T07:19:38.215Z', '2022-11-06T14:29:37.848Z',
'2022-11-06T07:27:18.650Z', '2022-11-06T07:13:16.876Z'],
dtype='<U24') s2:water_percentage
(time)
object
0.062349 0.488655 ... 0 0.004161
array([0.062349, 0.488655, 0.045153, 0.053586, 0.199773, 0.040334,
0.093679, 0.149412, 0.017018, 0.322026, 0.022672, 0.055551,
0.110587, 0.002531, 0.178901, 0.122335, 0.004535, 0.271276,
0.023153, 0.083391, 0, 0, 0, 0.004161], dtype=object) s2:unclassified_percentage
(time)
object
7.891426 7.111656 ... 0.000246 0
array([7.891426, 7.111656, 5.403911, 7.268476, 6.939063, 5.419557,
2.878225, 1.075694, 4.299427, 2.417318, 3.95306, 2.065491,
5.884444, 3.221869, 2.325676, 0.666839, 3.919373, 2.026642,
3.469541, 1.225461, 0.142235, 0.607874, 0.000246, 0], dtype=object) s2:sequence
()
<U1
'0'
eo:cloud_cover
(time)
float64
20.28 20.47 26.03 ... 96.83 95.96
array([20.283781, 20.472299, 26.031335, 38.931786, 14.514652, 8.532496,
0.946059, 2.044833, 1.519077, 0.749945, 2.244557, 1.396518,
1.940991, 1.007492, 1.704533, 0.160714, 0.667991, 0.672503,
0.246931, 1.038391, 99.489532, 97.991778, 96.828108, 95.96016 ]) earthsearch:s3_path
(time)
<U79
's3://sentinel-cogs/sentinel-s2-...
array(['s3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DA/2020/4/S2B_13SDA_20200401_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CA/2020/4/S2B_13SCA_20200401_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DV/2020/4/S2B_13SDV_20200401_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CV/2020/4/S2B_13SCV_20200401_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DA/2020/4/S2A_13SDA_20200403_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CA/2020/4/S2A_13SCA_20200403_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DV/2020/4/S2A_13SDV_20200403_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CV/2020/4/S2A_13SCV_20200403_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DA/2020/4/S2A_13SDA_20200406_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CA/2020/4/S2A_13SCA_20200406_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DV/2020/4/S2A_13SDV_20200406_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CV/2020/4/S2A_13SCV_20200406_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DA/2020/4/S2B_13SDA_20200408_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CA/2020/4/S2B_13SCA_20200408_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DV/2020/4/S2B_13SDV_20200408_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CV/2020/4/S2B_13SCV_20200408_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DA/2020/4/S2B_13SDA_20200411_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CA/2020/4/S2B_13SCA_20200411_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DV/2020/4/S2B_13SDV_20200411_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CV/2020/4/S2B_13SCV_20200411_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DA/2020/4/S2A_13SDA_20200413_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CA/2020/4/S2A_13SCA_20200413_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/DV/2020/4/S2A_13SDV_20200413_0_L2A',
's3://sentinel-cogs/sentinel-s2-l2a-cogs/13/S/CV/2020/4/S2A_13SCV_20200413_0_L2A'],
dtype='<U79') s2:high_proba_clouds_percentage
(time)
float64
12.02 11.28 20.02 ... 11.56 19.41
array([1.2023346e+01, 1.1275066e+01, 2.0020688e+01, 2.3646806e+01,
9.2994120e+00, 4.7001540e+00, 1.8538100e-01, 1.2239050e+00,
5.5752400e-01, 2.8377800e-01, 1.7221000e-02, 1.0368600e-01,
4.6470300e-01, 3.1231000e-01, 9.6588600e-01, 7.2297000e-02,
1.2965000e-01, 2.1773700e-01, 8.6335000e-02, 4.3841900e-01,
1.9255219e+01, 1.6350611e+01, 1.1555343e+01, 1.9413455e+01]) s2:dark_features_percentage
(time)
object
5.196252 5.139336 4.251513 ... 0 0
array([5.196252, 5.139336, 4.251513, 2.845578, 4.714508, 4.736075,
0.411445, 1.231329, 2.955875, 0.925627, 1.884744, 0.801497,
1.232087, 0.572857, 0.47257, 0.230118, 2.504361, 0.880475,
1.734854, 1.028099, 0.002376, 0.037088, 0, 0], dtype=object) s2:vegetation_percentage
(time)
object
6.700515 4.978285 6.331863 ... 0 0
array([6.700515, 4.978285, 6.331863, 2.400231, 8.64889, 8.807231,
13.711172, 2.427493, 8.710998, 9.125691, 12.844732, 5.445028,
11.992184, 10.253259, 13.592032, 2.572615, 9.663161, 9.391999,
13.822255, 5.950993, 0, 0, 0, 0], dtype=object) s2:granule_id
(time)
<U62
'S2B_OPER_MSI_L2A_TL_EPAE_202004...
array(['S2B_OPER_MSI_L2A_TL_EPAE_20200401T220155_A016040_T13SDA_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200401T220155_A016040_T13SCA_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200401T220155_A016040_T13SDV_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200401T220155_A016040_T13SCV_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200403T220105_A024977_T13SDA_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200403T220105_A024977_T13SCA_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200403T220105_A024977_T13SDV_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200403T220105_A024977_T13SCV_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200406T221027_A025020_T13SDA_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200406T221027_A025020_T13SCA_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200406T221027_A025020_T13SDV_N02.14',
'S2A_OPER_MSI_L2A_TL_SGS__20200406T221027_A025020_T13SCV_N02.14',
'S2B_OPER_MSI_L2A_TL_SGS__20200408T215856_A016140_T13SDA_N02.14',
'S2B_OPER_MSI_L2A_TL_SGS__20200408T215856_A016140_T13SCA_N02.14',
'S2B_OPER_MSI_L2A_TL_SGS__20200408T215856_A016140_T13SDV_N02.14',
'S2B_OPER_MSI_L2A_TL_SGS__20200408T215856_A016140_T13SCV_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200411T220443_A016183_T13SDA_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200411T220443_A016183_T13SCA_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200411T220443_A016183_T13SDV_N02.14',
'S2B_OPER_MSI_L2A_TL_EPAE_20200411T220443_A016183_T13SCV_N02.14',
'S2A_OPER_MSI_L2A_TL_MPS__20200413T235616_A025120_T13SDA_N02.14',
'S2A_OPER_MSI_L2A_TL_MPS__20200413T235616_A025120_T13SCA_N02.14',
'S2A_OPER_MSI_L2A_TL_MPS__20200413T235616_A025120_T13SDV_N02.14',
'S2A_OPER_MSI_L2A_TL_MPS__20200413T235616_A025120_T13SCV_N02.14'],
dtype='<U62') mgrs:grid_square
(time)
<U2
'DA' 'CA' 'DV' ... 'CA' 'DV' 'CV'
array(['DA', 'CA', 'DV', 'CV', 'DA', 'CA', 'DV', 'CV', 'DA', 'CA', 'DV',
'CV', 'DA', 'CA', 'DV', 'CV', 'DA', 'CA', 'DV', 'CV', 'DA', 'CA',
'DV', 'CV'], dtype='<U2') earthsearch:payload_id
(time)
<U74
'roda-sentinel2/workflow-sentine...
array(['roda-sentinel2/workflow-sentinel2-to-stac/99e88e033f629d82f391d4e8e34899e2',
'roda-sentinel2/workflow-sentinel2-to-stac/37bf8aa0d469eee544ae2952da07f291',
'roda-sentinel2/workflow-sentinel2-to-stac/afb43c585d466972865ed5139ba35520',
'roda-sentinel2/workflow-sentinel2-to-stac/ad0860669f6fb9efa4815b6460d4df26',
'roda-sentinel2/workflow-sentinel2-to-stac/9709b972eb0ed6691e38c1086505bab6',
'roda-sentinel2/workflow-sentinel2-to-stac/bea47a6effd710215d3e764393db3031',
'roda-sentinel2/workflow-sentinel2-to-stac/00bfe5eff22b9aae0b5adfae696a11fa',
'roda-sentinel2/workflow-sentinel2-to-stac/a4fbecf50e4b3d8ff56c362272200c54',
'roda-sentinel2/workflow-sentinel2-to-stac/9681d361aad69923e267f931f7204ae4',
'roda-sentinel2/workflow-sentinel2-to-stac/6c7afc2bb3931300e1d2321c433eee52',
'roda-sentinel2/workflow-sentinel2-to-stac/2758e5e900c1639f19b11efe3fbbbc26',
'roda-sentinel2/workflow-sentinel2-to-stac/4d535a1644bacc32bf91ce0b05577091',
'roda-sentinel2/workflow-sentinel2-to-stac/f7fccfccb78beb998321297c13561d58',
'roda-sentinel2/workflow-sentinel2-to-stac/b115d03670688ca0a748d0f203834b14',
'roda-sentinel2/workflow-sentinel2-to-stac/861d7837603c47c9badccf7641222c43',
'roda-sentinel2/workflow-sentinel2-to-stac/032d1e9a1eec4aeb962d1c3b549fa56a',
'roda-sentinel2/workflow-sentinel2-to-stac/7472bd282e706e3ac17fdbbaa80cf06f',
'roda-sentinel2/workflow-sentinel2-to-stac/03306a7a93a9397a6d04cfa4b4b853fe',
'roda-sentinel2/workflow-sentinel2-to-stac/d00c2b2ec66eb2ee26e3c9c77c92924d',
'roda-sentinel2/workflow-sentinel2-to-stac/46e3f21e169659ba38796527cad1fb3c',
'roda-sentinel2/workflow-sentinel2-to-stac/0e4dff9d1de2ed545d38b90245bff1bc',
'roda-sentinel2/workflow-sentinel2-to-stac/0ce848612c97c3a26dfbd0cdcd312b98',
'roda-sentinel2/workflow-sentinel2-to-stac/f1e8d6da18b30cec574888940cda178d',
'roda-sentinel2/workflow-sentinel2-to-stac/b3992f61071775508a0a2b00fa70d871'],
dtype='<U74') s2:product_uri
(time)
<U65
'S2B_MSIL2A_20200401T174909_N021...
array(['S2B_MSIL2A_20200401T174909_N0214_R141_T13SDA_20200401T220155.SAFE',
'S2B_MSIL2A_20200401T174909_N0214_R141_T13SCA_20200401T220155.SAFE',
'S2B_MSIL2A_20200401T174909_N0214_R141_T13SDV_20200401T220155.SAFE',
'S2B_MSIL2A_20200401T174909_N0214_R141_T13SCV_20200401T220155.SAFE',
'S2A_MSIL2A_20200403T173901_N0214_R098_T13SDA_20200403T220105.SAFE',
'S2A_MSIL2A_20200403T173901_N0214_R098_T13SCA_20200403T220105.SAFE',
'S2A_MSIL2A_20200403T173901_N0214_R098_T13SDV_20200403T220105.SAFE',
'S2A_MSIL2A_20200403T173901_N0214_R098_T13SCV_20200403T220105.SAFE',
'S2A_MSIL2A_20200406T174901_N0214_R141_T13SDA_20200406T221027.SAFE',
'S2A_MSIL2A_20200406T174901_N0214_R141_T13SCA_20200406T221027.SAFE',
'S2A_MSIL2A_20200406T174901_N0214_R141_T13SDV_20200406T221027.SAFE',
'S2A_MSIL2A_20200406T174901_N0214_R141_T13SCV_20200406T221027.SAFE',
'S2B_MSIL2A_20200408T173859_N0214_R098_T13SDA_20200408T215856.SAFE',
'S2B_MSIL2A_20200408T173859_N0214_R098_T13SCA_20200408T215856.SAFE',
'S2B_MSIL2A_20200408T173859_N0214_R098_T13SDV_20200408T215856.SAFE',
'S2B_MSIL2A_20200408T173859_N0214_R098_T13SCV_20200408T215856.SAFE',
'S2B_MSIL2A_20200411T174909_N0214_R141_T13SDA_20200411T220443.SAFE',
'S2B_MSIL2A_20200411T174909_N0214_R141_T13SCA_20200411T220443.SAFE',
'S2B_MSIL2A_20200411T174909_N0214_R141_T13SDV_20200411T220443.SAFE',
'S2B_MSIL2A_20200411T174909_N0214_R141_T13SCV_20200411T220443.SAFE',
'S2A_MSIL2A_20200413T173901_N0214_R098_T13SDA_20200413T235616.SAFE',
'S2A_MSIL2A_20200413T173901_N0214_R098_T13SCA_20200413T235616.SAFE',
'S2A_MSIL2A_20200413T173901_N0214_R098_T13SDV_20200413T235616.SAFE',
'S2A_MSIL2A_20200413T173901_N0214_R098_T13SCV_20200413T235616.SAFE'],
dtype='<U65') created
(time)
<U24
'2022-11-06T14:31:19.801Z' ... '...
array(['2022-11-06T14:31:19.801Z', '2022-11-03T10:59:12.965Z',
'2022-11-06T10:14:16.681Z', '2022-11-06T10:15:25.721Z',
'2022-11-03T17:27:26.049Z', '2022-11-03T11:22:07.730Z',
'2022-11-06T07:21:36.990Z', '2022-11-03T17:17:05.299Z',
'2022-11-06T07:05:45.085Z', '2022-11-03T11:22:15.486Z',
'2022-11-06T10:14:20.981Z', '2022-11-06T07:20:38.463Z',
'2022-11-06T07:06:10.399Z', '2022-11-06T07:37:18.786Z',
'2022-11-06T10:14:26.677Z', '2022-11-06T07:19:38.224Z',
'2022-11-06T14:31:20.528Z', '2022-11-06T14:29:35.970Z',
'2022-11-06T10:14:16.074Z', '2022-11-06T07:13:16.911Z',
'2022-11-06T07:19:38.215Z', '2022-11-06T14:29:37.848Z',
'2022-11-06T07:27:18.650Z', '2022-11-06T07:13:16.876Z'],
dtype='<U24') s2:thin_cirrus_percentage
()
int64
0
s2:datatake_type
()
<U8
'INS-NOBS'
array('INS-NOBS', dtype='<U8') s2:cloud_shadow_percentage
(time)
object
1.243385 1.087601 1.063333 ... 0 0
array([1.243385, 1.087601, 1.063333, 0.357972, 1.60302, 0.800865,
0.143752, 0.12813, 0.728509, 0.217348, 0.382583, 0.035906,
0.544641, 0.157477, 0.408436, 0.001802, 0.484926, 0.186808,
0.333179, 0.244857, 0, 0, 0, 0], dtype=object) platform
(time)
<U11
'sentinel-2b' ... 'sentinel-2a'
array(['sentinel-2b', 'sentinel-2b', 'sentinel-2b', 'sentinel-2b',
'sentinel-2a', 'sentinel-2a', 'sentinel-2a', 'sentinel-2a',
'sentinel-2a', 'sentinel-2a', 'sentinel-2a', 'sentinel-2a',
'sentinel-2b', 'sentinel-2b', 'sentinel-2b', 'sentinel-2b',
'sentinel-2b', 'sentinel-2b', 'sentinel-2b', 'sentinel-2b',
'sentinel-2a', 'sentinel-2a', 'sentinel-2a', 'sentinel-2a'],
dtype='<U11') proj:epsg
()
int64
32613
s2:reflectance_conversion_factor
(time)
float64
1.004 1.004 1.004 ... 0.9967 0.9967
array([1.00356284, 1.00356284, 1.00356284, 1.00356284, 1.00241536,
1.00241536, 1.00241536, 1.00241536, 1.00068285, 1.00068285,
1.00068285, 1.00068285, 0.99953571, 0.99953571, 0.99953571,
0.99953571, 0.99781012, 0.99781012, 0.99781012, 0.99781012,
0.99667185, 0.99667185, 0.99667185, 0.99667185]) s2:datatake_id
(time)
<U34
'GS2B_20200401T174909_016040_N02...
array(['GS2B_20200401T174909_016040_N02.14',
'GS2B_20200401T174909_016040_N02.14',
'GS2B_20200401T174909_016040_N02.14',
'GS2B_20200401T174909_016040_N02.14',
'GS2A_20200403T173901_024977_N02.14',
'GS2A_20200403T173901_024977_N02.14',
'GS2A_20200403T173901_024977_N02.14',
'GS2A_20200403T173901_024977_N02.14',
'GS2A_20200406T174901_025020_N02.14',
'GS2A_20200406T174901_025020_N02.14',
'GS2A_20200406T174901_025020_N02.14',
'GS2A_20200406T174901_025020_N02.14',
'GS2B_20200408T173859_016140_N02.14',
'GS2B_20200408T173859_016140_N02.14',
'GS2B_20200408T173859_016140_N02.14',
'GS2B_20200408T173859_016140_N02.14',
'GS2B_20200411T174909_016183_N02.14',
'GS2B_20200411T174909_016183_N02.14',
'GS2B_20200411T174909_016183_N02.14',
'GS2B_20200411T174909_016183_N02.14',
'GS2A_20200413T173901_025120_N02.14',
'GS2A_20200413T173901_025120_N02.14',
'GS2A_20200413T173901_025120_N02.14',
'GS2A_20200413T173901_025120_N02.14'], dtype='<U34') s2:processing_baseline
()
<U5
'02.14'
array('02.14', dtype='<U5') processing:software
()
object
{'sentinel2-to-stac': '0.1.0'}
array({'sentinel2-to-stac': '0.1.0'}, dtype=object) s2:generation_time
(time)
<U27
'2020-04-01T22:01:55.000000Z' .....
array(['2020-04-01T22:01:55.000000Z', '2020-04-01T22:01:55.000000Z',
'2020-04-01T22:01:55.000000Z', '2020-04-01T22:01:55.000000Z',
'2020-04-03T22:01:05.000000Z', '2020-04-03T22:01:05.000000Z',
'2020-04-03T22:01:05.000000Z', '2020-04-03T22:01:05.000000Z',
'2020-04-06T22:10:27.000000Z', '2020-04-06T22:10:27.000000Z',
'2020-04-06T22:10:27.000000Z', '2020-04-06T22:10:27.000000Z',
'2020-04-08T21:58:56.000000Z', '2020-04-08T21:58:56.000000Z',
'2020-04-08T21:58:56.000000Z', '2020-04-08T21:58:56.000000Z',
'2020-04-11T22:04:43.000000Z', '2020-04-11T22:04:43.000000Z',
'2020-04-11T22:04:43.000000Z', '2020-04-11T22:04:43.000000Z',
'2020-04-13T23:56:16.000000Z', '2020-04-13T23:56:16.000000Z',
'2020-04-13T23:56:16.000000Z', '2020-04-13T23:56:16.000000Z'],
dtype='<U27') s2:degraded_msi_data_percentage
()
int64
0
s2:saturated_defective_pixel_percentage
()
int64
0
s2:medium_proba_clouds_percentage
(time)
float64
8.26 9.197 6.011 ... 85.27 76.55
array([ 8.260435, 9.197233, 6.010647, 15.284979, 5.215239, 3.832341,
0.760678, 0.820928, 0.961553, 0.466166, 2.227335, 1.292832,
1.476288, 0.695182, 0.738647, 0.088417, 0.538341, 0.454766,
0.160596, 0.599972, 80.234313, 81.641167, 85.272765, 76.546705]) s2:product_type
()
<U7
'S2MSI2A'
array('S2MSI2A', dtype='<U7') instruments
()
<U3
'msi'
array('msi', dtype='<U3') view:sun_azimuth
(time)
float64
152.2 150.4 151.7 ... 145.3 143.4
array([152.16561904, 150.38618546, 151.65028202, 149.86343304,
147.87388548, 146.15062636, 147.27598521, 145.55024524,
151.45609349, 149.60220583, 150.88270509, 149.01962366,
146.97599907, 145.18827002, 146.31202768, 144.52098552,
150.65811328, 148.72664606, 150.01908475, 148.07653379,
145.99466812, 144.14086161, 145.2568735 , 143.39908426]) view:sun_elevation
(time)
float64
55.34 54.93 56.16 ... 59.51 59.0
array([55.34352909, 54.92630927, 56.16432002, 55.73980166, 55.09937783,
54.62452421, 55.88951512, 55.40664384, 57.23862625, 56.81124166,
58.0544818 , 57.61906743, 56.94924169, 56.46228175, 57.73216728,
57.23642132, 59.0735396 , 58.63486421, 59.88368207, 59.43614614,
58.73516936, 58.23514389, 59.50994522, 59.00029953]) s2:nodata_pixel_percentage
(time)
object
41.639832 7e-06 ... 0 57.184404
array([41.639832, 7e-06, 66.037267, 0, 0.017774, 79.928863, 0, 57.768804,
41.532966, 1.3e-05, 65.976346, 3e-06, 0.005756, 79.546475, 3e-06,
57.458252, 41.612193, 0, 66.008884, 7e-06, 0.002077, 79.343802, 0,
57.184404], dtype=object) constellation
()
<U10
'sentinel-2'
array('sentinel-2', dtype='<U10') s2:not_vegetated_percentage
(time)
object
52.133548 48.725316 ... 0 0
array([52.133548, 48.725316, 53.858513, 45.037875, 55.706638, 67.469364,
77.119505, 92.122465, 74.830645, 73.836285, 72.610897, 87.454349,
70.887482, 82.498342, 78.381914, 95.616364, 77.449673, 76.24802,
75.565374, 88.838291, 0.358138, 1.362797, 0, 0], dtype=object) s2:datastrip_id
(time)
<U64
'S2B_OPER_MSI_L2A_DS_EPAE_202004...
array(['S2B_OPER_MSI_L2A_DS_EPAE_20200401T220155_S20200401T175716_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200401T220155_S20200401T175716_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200401T220155_S20200401T175716_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200401T220155_S20200401T175716_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200403T220105_S20200403T174815_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200403T220105_S20200403T174815_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200403T220105_S20200403T174815_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200403T220105_S20200403T174815_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200406T221027_S20200406T175657_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200406T221027_S20200406T175657_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200406T221027_S20200406T175657_N02.14',
'S2A_OPER_MSI_L2A_DS_SGS__20200406T221027_S20200406T175657_N02.14',
'S2B_OPER_MSI_L2A_DS_SGS__20200408T215856_S20200408T174547_N02.14',
'S2B_OPER_MSI_L2A_DS_SGS__20200408T215856_S20200408T174547_N02.14',
'S2B_OPER_MSI_L2A_DS_SGS__20200408T215856_S20200408T174547_N02.14',
'S2B_OPER_MSI_L2A_DS_SGS__20200408T215856_S20200408T174547_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200411T220443_S20200411T175522_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200411T220443_S20200411T175522_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200411T220443_S20200411T175522_N02.14',
'S2B_OPER_MSI_L2A_DS_EPAE_20200411T220443_S20200411T175522_N02.14',
'S2A_OPER_MSI_L2A_DS_MPS__20200413T235616_S20200413T174358_N02.14',
'S2A_OPER_MSI_L2A_DS_MPS__20200413T235616_S20200413T174358_N02.14',
'S2A_OPER_MSI_L2A_DS_MPS__20200413T235616_S20200413T174358_N02.14',
'S2A_OPER_MSI_L2A_DS_MPS__20200413T235616_S20200413T174358_N02.14'],
dtype='<U64') grid:code
(time)
<U10
'MGRS-13SDA' ... 'MGRS-13SCV'
array(['MGRS-13SDA', 'MGRS-13SCA', 'MGRS-13SDV', 'MGRS-13SCV',
'MGRS-13SDA', 'MGRS-13SCA', 'MGRS-13SDV', 'MGRS-13SCV',
'MGRS-13SDA', 'MGRS-13SCA', 'MGRS-13SDV', 'MGRS-13SCV',
'MGRS-13SDA', 'MGRS-13SCA', 'MGRS-13SDV', 'MGRS-13SCV',
'MGRS-13SDA', 'MGRS-13SCA', 'MGRS-13SDV', 'MGRS-13SCV',
'MGRS-13SDA', 'MGRS-13SCA', 'MGRS-13SDV', 'MGRS-13SCV'],
dtype='<U10') s2:snow_ice_percentage
(time)
float64
6.489 12.0 3.014 ... 3.172 4.036
array([6.4887500e+00, 1.1996852e+01, 3.0143800e+00, 3.1044990e+00,
7.6734550e+00, 4.1940760e+00, 4.6961620e+00, 8.2064500e-01,
6.9384490e+00, 1.2405753e+01, 6.0567560e+00, 2.7456580e+00,
7.4075860e+00, 2.2861730e+00, 2.9359330e+00, 6.2920900e-01,
5.3059740e+00, 1.0322275e+01, 4.8047150e+00, 1.5905220e+00,
7.7170000e-03, 4.6600000e-04, 3.1716480e+00, 4.0356810e+00]) mgrs:latitude_band
()
<U1
'S'
earthsearch:boa_offset_applied
()
bool
False
title
(band)
<U31
'Red (band 4) - 10m' ... 'Blue (...
array(['Red (band 4) - 10m', 'Green (band 3) - 10m',
'Blue (band 2) - 10m'], dtype='<U31') raster:bands
(band)
object
[{'nodata': 0, 'data_type': 'uin...
array([list([{'nodata': 0, 'data_type': 'uint16', 'bits_per_sample': 15, 'spatial_resolution': 10, 'scale': 0.0001, 'offset': 0}]),
list([{'nodata': 0, 'data_type': 'uint16', 'bits_per_sample': 15, 'spatial_resolution': 10, 'scale': 0.0001, 'offset': 0}]),
list([{'nodata': 0, 'data_type': 'uint16', 'bits_per_sample': 15, 'spatial_resolution': 10, 'scale': 0.0001, 'offset': 0}])],
dtype=object) gsd
(band)
object
10 10 10
array([10, 10, 10], dtype=object) common_name
(band)
object
'red' 'green' 'blue'
array(['red', 'green', 'blue'], dtype=object) center_wavelength
(band)
object
0.665 0.56 0.49
array([0.665, 0.56, 0.49], dtype=object) full_width_half_max
(band)
object
0.038 0.045 0.098
array([0.038, 0.045, 0.098], dtype=object) epsg
()
int64
32613
Indexes: (4)
PandasIndex
PandasIndex(DatetimeIndex(['2020-04-01 18:03:50.186000', '2020-04-01 18:03:54.215000',
'2020-04-01 18:04:04.327000', '2020-04-01 18:04:08.595000',
'2020-04-03 17:53:53.071000', '2020-04-03 17:53:57.251000',
'2020-04-03 17:54:07.524000', '2020-04-03 17:54:10.679000',
'2020-04-06 18:03:49.954000', '2020-04-06 18:03:53.989000',
'2020-04-06 18:04:04.095000', '2020-04-06 18:04:08.369000',
'2020-04-08 17:53:53.544000', '2020-04-08 17:53:57.705000',
'2020-04-08 17:54:08.005000', '2020-04-08 17:54:11.154000',
'2020-04-11 18:03:49.084000', '2020-04-11 18:03:53.113000',
'2020-04-11 18:04:03.225000', '2020-04-11 18:04:07.492000',
'2020-04-13 17:53:56.019000', '2020-04-13 17:54:00.148000',
'2020-04-13 17:54:10.480000', '2020-04-13 17:54:13.625000'],
dtype='datetime64[ns]', name='time', freq=None)) PandasIndex
PandasIndex(Index(['red', 'green', 'blue'], dtype='object', name='band')) PandasIndex
PandasIndex(Float64Index([300000.0, 300080.0, 300160.0, 300240.0, 300320.0, 300400.0,
300480.0, 300560.0, 300640.0, 300720.0,
...
508960.0, 509040.0, 509120.0, 509200.0, 509280.0, 509360.0,
509440.0, 509520.0, 509600.0, 509680.0],
dtype='float64', name='x', length=2622)) PandasIndex
PandasIndex(Float64Index([4100080.0, 4100000.0, 4099920.0, 4099840.0, 4099760.0, 4099680.0,
4099600.0, 4099520.0, 4099440.0, 4099360.0,
...
3890960.0, 3890880.0, 3890800.0, 3890720.0, 3890640.0, 3890560.0,
3890480.0, 3890400.0, 3890320.0, 3890240.0],
dtype='float64', name='y', length=2624)) Attributes: (4)
spec : RasterSpec(epsg=32613, bounds=(300000, 3890160, 509760, 4100080), resolutions_xy=(80, 80)) crs : epsg:32613 transform : | 80.00, 0.00, 300000.00|
| 0.00,-80.00, 4100080.00|
| 0.00, 0.00, 1.00| resolution : 80
stackstac.add_to_map stackstac.add_to_map add_to_map
Before continuing, you should open the distributed dashboard in another window (or use the dask-jupyterlab extension) in order to watch its progress.
Static screenshot for docs (delete this cell if running the notebook):
stackstac.server_stats
Make a temporal median composite, and show that on the map m
Try changing median mean min max "s2"
Showing computed values
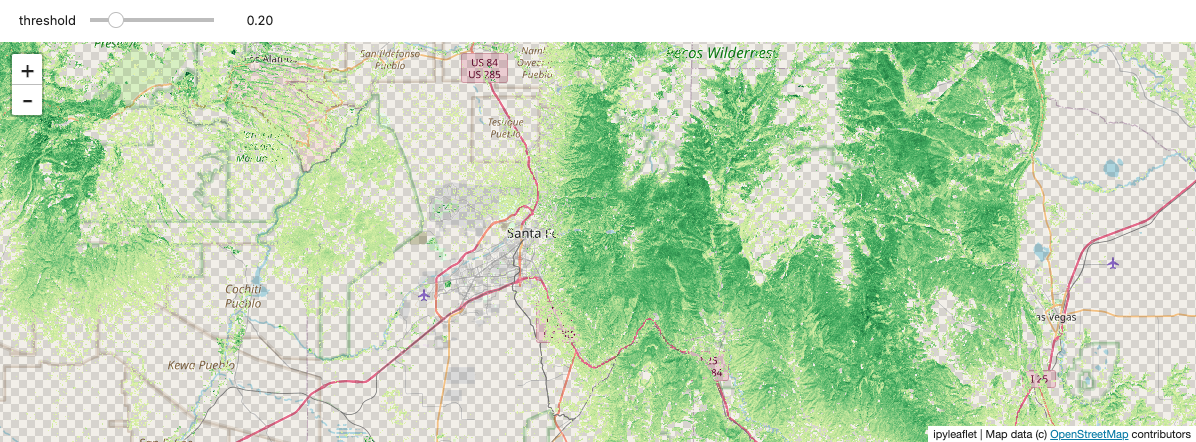
You can display anything you can compute with dask and xarray, not just raw data. Here, we’ll compute NDVI (Normalized Difference Vegetation Index), which indicates the health of vegetation (and is kind of a “hello world” example for remote sensing).
We’ll show the temporal maximum NDVI (try changing to min median
stackstac.show stackstac.show
Static screenshot for docs (delete this cell if running the notebook):
To demonstrate more derived quantities: show each pixel’s deviation from the mean NDVI of the whole array:
/Users/gabe/dev/stackstac/.venv/lib/python3.9/site-packages/stackstac/show.py:484: UserWarning: Calculating 2nd and 98th percentile of the entire array, since no range was given. This could be expensive!
warnings.warn(
Static screenshot for docs (delete this cell if running the notebook):